近日,第51届IEEE国际声学、语音与信号处理会议(ICASSP 2026)于西班牙巴塞罗那顺利举办。作为全球信号处理领域规模最大、覆盖最全面的顶级学术会议,ICASSP 是 IEEE 信号处理学会旗舰会议,同时入选中国计算机学会(CCF)B类国际学术会议,在国际学界拥有广泛影响力与权威认可度。
本次会议上,天津大学电气自动化与信息工程学院张涛团队在语音增强方向取得重要创新突破,两项研究工作被大会正式录用并完成现场汇报。学院青年教师、团队通讯作者耿彦章赴巴塞罗那会议中心参会,与全球领域内专家开展深度学术交流。此次展示成果聚焦生成式语音增强与极低信噪比多通道语音增强两大前沿方向,展现了团队在复杂声学信号处理上的技术优势。
成果一:基于状态依赖马尔可夫扩散过程(SDMDP)的生成式语音增强
在单通道语音增强方面,传统扩散模型通常采用固定噪声调度策略,难以适配动态变化、非平稳的实际噪声场景。针对这一痛点,团队成员Yasir Iqbal等人提出状态依赖马尔可夫扩散过程(SDMDP)新方法 。
该方法通过自适应调整状态转移速率,实时匹配输入噪声特性,有效加快模型收敛速度并提升增强效果。结合图注意力门控U-Net(GUGA)结构与混合感知损失函数,所提模型在多项客观指标上达到国际先进水平:PESQ达3.84、SI-SDR 达20.1dB,在语音质量与处理效率上全面优于现有判别式与生成式基准模型。
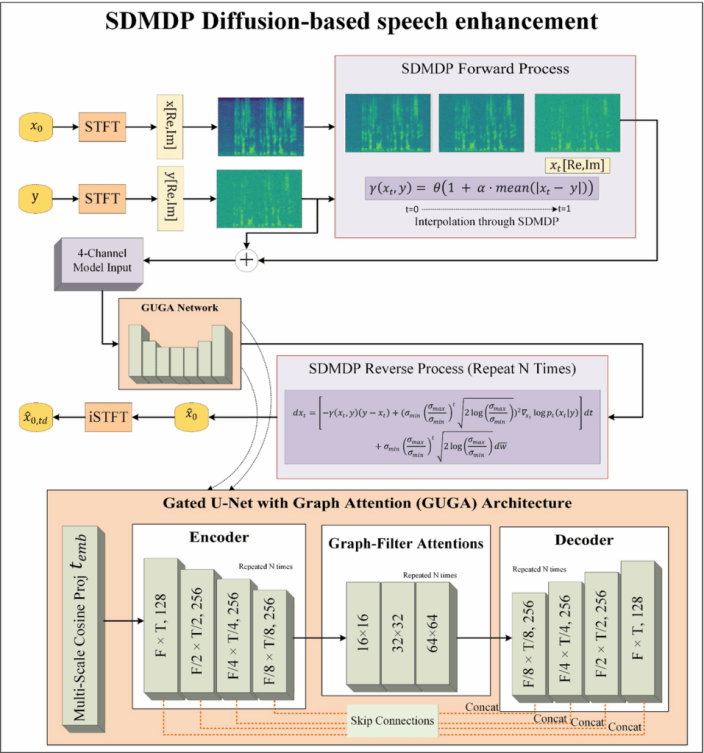
基于门控 U-Net 与图注意力(GUGA)架构的状态相关马尔可夫决策过程(SDMDP)框架在语音增强中的应用。
耿彦章在ICASSP会议现场,向参会学者详细讲解基于SDMDP机制的生成式语音增强研究成果
成果二:S-PHiNe——面向低信噪比环境的物理驱动多通道语音增强
在恶劣噪声环境下的多通道语音增强(MCSE)长期面临技术挑战。针对- 20 dB至0dB极端低信噪比场景,团队Stephen Afrifa等提出S-PHiNe架构,实现频谱特征与空间特征的高效融合。 。
S-PHiNe为物理信息驱动的端到端框架,有机融合深度图卷积网络(DGCN)空间嵌入、复数波束形成神经网络(CBNN)与物理约束最小方差无失真响应(MVDR)波束形成器。测试结果显示,该模型在语音可懂度、主观听觉质量与跨通道泛化能力上优于当前主流神经后滤波与波束形成方案,为高噪声条件下多通道语音处理提供了稳定可靠的技术路径。
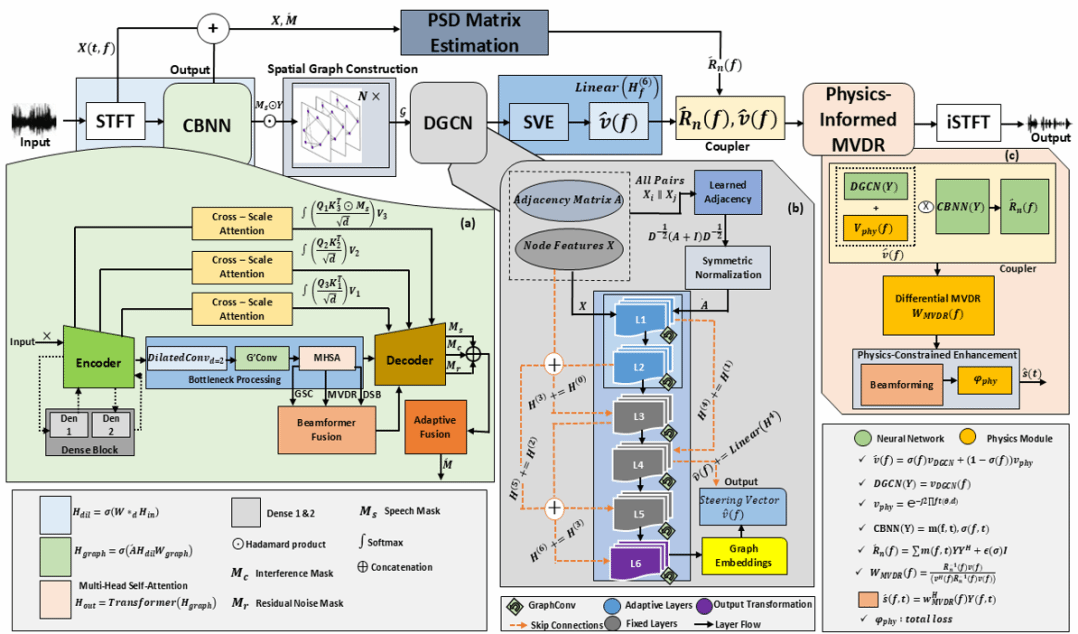
模型的整体框架:(a)卷积双向循环神经网络(CBNN)(b)动态图卷积网络(DGCN)(c)受物理约束的 MVDR 训练网络

在本届 ICASSP 会议中,天津大学团队充分展现了在复杂声学信号处理领域的科研实力。未来,团队将进一步优化模型推理速度,向实时部署方向推进,并将核心框架拓展应用到语音分离、带宽扩展等更多音频处理任务中,持续产出高质量研究成果。
